
3次元データへの深層学習の適用
はじめに
カブクで深層学習を用いたプロダクト開発をしている大串正矢です。今回は3次元データの検索エンジン作成のために用いた手法であるVoxNetについて書きます。
背景
弊社はお客様から図面のデータを3次元図面で頂く場合があります。その時に図面データだけを入力して過去の情報と照らし合わせることができれば図面のデータに対する知識の度合いに関わらず対応できます。このようなスキル差を埋めて欲しいニーズがあるため3次元データの検索エンジンを作成しています。3次元データの検索エンジンの一部のモジュールにVoxNetで作成した深層学習モデルを使用しています。
VoxNet
VoxNetとは、3次元データをサイズが限定されたx-y-z空間上に写像し(ボクセル化)、その3次元情報を3次元CNNの入力として学習させる方法です。ここでは”Voxnet: A 3d convolutional neural network for real-time object recognition”に記載のサイズである323232のボクセルを採用しています。
画像は下記論文から引用しています。
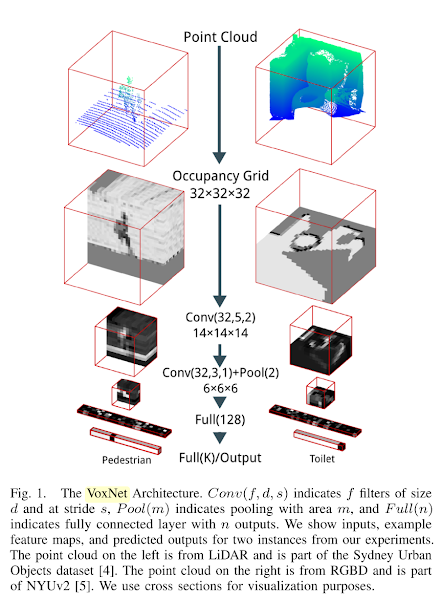
Maturana, Daniel, and Sebastian Scherer. “Voxnet: A 3d convolutional neural network for real-time object recognition.” Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015.
ボクセル化の手順
1. 各軸の最長距離(最大値と最小値の差)を求める。
2. 中央値が0になるよう各点を移動する。
3. 最長距離を分割したい数から4引いた数(今回は28)で割った値を算出する。(※ボクセルの両端を0でpaddingし、さらに少数の丸め誤差を考慮にいれ、分割数から4を引いている)
4. 3で算出した値で各点を割る。これで各点は(-15, 15)の範囲の値になる。
5. 各点を最も近い整数に丸める。これで各点は[-15, 15]の範囲の整数になる。
6. 各点が全て正の整数になるよう移動。これで各点は[0, 30]の範囲の整数になる。
7. 303030のデータセットに対し、点が存在する場合は1、存在しない場合は0を入力する。(※ここではさらに、点が存在しても20%の確率で0とし、データにノイズを加え、汎用性を上げている)
8. 323232のデータセットの両端の点を0にして残りの座標に先ほど作成したデータセットを代入。これで両端が0でpaddingされたボクセルデータが完成する。
下記のコードで上記手順を実現しています。
import numpy as np
import sys
TINY_NUMBER=sys.float_info.epsilon
max_dist = 0.0
for it in range(0, 3):
# find min max & distance in current direction
min = np.amin(np_pc[:, it])
max = np.amax(np_pc[:, it])
dist = max - min
# find maximum distance
if dist > max_dist:
max_dist = dist
# set middle to 0,0,0
np_pc[:, it] = np_pc[:, it] - dist / 2 - min
# covered cells
covered_cells = 29
# find voxel edge size
vox_sz = dist / (covered_cells - 1)
# if 0 divid
if vox_sz == 0:
vox_sz = TINY_NUMBER
# render pc to size 30x30x30 from middle
np_pc[:, it] = np_pc[:, it] / vox_sz
for it in range(0, 3):
np_pc[:, it] = np_pc[:, it] + (covered_cells - 1) / 2
# round to integer array
np_pc = np.rint(np_pc).astype(np.uint32)
# fill voxel arrays
vox = np.zeros([30, 30, 30])
for (pc_x, pc_y, pc_z) in np_pc:
if random.randint(0, 100) < 80:
vox[pc_x, pc_y, pc_z] = 1.0
np_vox = np.zeros([1, 32, 32, 32])
np_vox[0, 1:-1, 1:-1, 1:-1] = vox
VoxNetを選んだ理由
3次元データの場合、2次元画像に比べると情報量が多くなります。理論上学習できるとしても計算量やリソースの問題でそもそも使えないということが問題になります。VoxNetはその点をクリアしているためシングルGPUでも現実的な時間で学習できるようになっています。
独自の深層学習モデルをゼロから全て実装するには試行錯誤の時間も含めて多大な時間を要するため、すでに研究・実装されているコードを探して、その中から選択することにしました。
今回はKerasを選択しました。実装コストが少なく、チューニングが必要になった場合はTensorFlowへの移行が比較的容易と考えKerasを採用しました。
参考にさせて頂いたコードは下記
3次元CNNとは
Kerasの場合は2次元のCNNは入力層が4次元(データ数、x座標データ、y座標データ、画素数)になります。3次元のデータの場合は5次元となり(データ数、x座標データ、y座標データ、z座標データ、画素数)が入力層に入ります。
データの並び順はKerasがバックエンドとしてサポートするTensorFlowとTheanoで異なるので注意が必要です。(※ここではTensorFlowを利用する場合を例にしています)
下記の動画は次元が時間軸の3次元データですが、3次元CNNの分かりやすい解説になっています。前半は2次元画像のCNNについての説明で、82秒からが3次元CNNの説明です。
今回使用した深層学習モデルのグラフ
次の図はTensroBoardを使用して実装したVoxNetのモデルを表示しています。TensorBoardは使用しているモデルの構造の関係が分かり、知識共有に有用になるのでオススメです。また、OptimizerにAdamを適用しました。

工夫した点
カリキュラムラーニング
学習データの難易度をData augmentationの手法とパラメータでコントロール可能であると仮説をたて、その場合に有用な手法として知られているカリキュラムラーニングを適用しました。
後述の通り、カリキュラムラーニングは最終的には採用しませんでした。
カリキュラムラーニングを行う際により各カリキュラムにおいて学習速度を上げるため幾つかのOptimizerを試しました。ロス率が設定したしきい値を下回った時に次のカリキュラムに進めるようにしました。次の7つのOptimizerを試しました。
SGDは学習速度が遅く、かつ、ロス率がしきい値以下で収束しませんでした。
SGD HD とAdam HD は学習率αを自動で調整する手法になります。カリキュラムラーニングではカリキュラムが進むごとに学習データが異なるため、学習率が適応的に変更される必要があると考え、この2手法に注目しました。Adam HDは学習速度が非常に速いのですが、しきい値以上のロス率で収束する傾向がありました。試行錯誤の結果、カリキュラムラーニングではバランスの取れたSGD HDを採用しました。
SGD HD と Adam HDについては下記の論文を参考にして実装しました。興味のある方は下記の論文をご参照ください。
Baydin, Atilim Gunes, et al. "Online Learning Rate Adaptation with Hypergradient Descent." arXiv preprint arXiv:1703.04782 (2017).
前処理、特徴量抽出処理毎にデータをファイルで保存
前処理や特徴量抽出は処理時間がかかります。この処理は一度行ったらファイルとして保存して再利用することで無駄な処理時間を削減しました。これによりトライアンドエラーの回数を増やせるので必須の処理になります。
転移学習
学習済みのモデルが公開されていたのでそのモデルのデータを使用しました。転移学習には下記のメリットがあります。
Data augmentation
2次元のData augmentationを3次元データにも適用できるように修正しました。学習データによって汎化性能を上げるアプローチが可能になるため選択肢が広がります。またモデル自身の汎化性能を向上させるアプローチとは違い、期待できる効果がある程度明確なため、事前の仮説が立てやすくなります。
Data augmentationの例(左からフリップ、シェア、ローテーションをかけています。)

計算速度向上
深層学習は失敗する回数が多い手法なのでいかに早く失敗するかが重要になります。今回行った学習速度向上の工夫は下記です。
TensorFlowのコードをソースコードからビルドしCPU最適化オプションをつけました。ただし計算機の環境によって動作しないオプションもあります。またTensorflowのバージョンは1.0.1になります。
どのオプションが使用可能かはTensorflowのwarningで確認できます。ソースからビルドせずにpipでインストールした場合に発生するオプションの例です。
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
上記の警告で示された命令オプションがCPUで使用可能な命令オプションで使用していないものになります。
SSE (Streaming SIMD Extensions)
4個の32ビット単精度浮動小数点データを一本のレジスタに格納し、同一の命令を一括処理することが出来る処理です。(Wikipedia参照)
AVX (Advanced Vector Extensions)
浮動小数点演算の演算幅がSSEの2倍の256ビットとなり、1命令で8つの単精度浮動小数点演算もしくは4つの倍精度浮動小数点演算を実行することができます。(Wikipedia参照)
FMA
x86プロセッサにおいて積和演算を実現するための拡張命令がFMAです。(Wikipedia参照)
FMA
下記でオプションをかけたビルドを実行します。
copt={設定したいCPU命令オプション}
bazelでビルドする場合の例
bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma
他の速度向上策としてData augmentationの処理をマルチスレッドで並列実行をかけました。これはバッチサイズに依存するのでそれほど効果が大きくはありませんでした。
Data augmentationを学習データにかけているためCPU処理周りの最適化とマルチスレッドの並列実行は学習の高速化に効果を発揮しました。これらの処理により学習速度は約2倍程度向上しました。
クラス重み
今回使用したデータは分類されたデータ数のバランスが良くないため、バリデーションデータにおける性能が良くありませんでした。そこでデータ数の逆数をクラス重みとして与えて学習させてアンバランスなデータにも適用できるようにしました。
工夫したがあまり効果が見られなかった点
今回はData augmentationの種類に合わせてカリキュラムを組み実行しました。手法自体は優秀だと思いますがリソースの問題と高速にトライアンドエラーを何回も行うことに向いておらず、途中から方法を変更しました。
計算リソースを多く割いたため、そもそも学習ができませんでした。
同じく計算リソースを多く割いたため、そもそも学習ができませんでした。
使用したデータ
下記の3次元データを使用しました。10クラスのデータと40クラスのデータは簡単に取得できますが、全クラスの3次元データの場合は申請が必要になります。
下記のサイトから取得できます。
ModelNet
Download 10-Class Orientation-aligned Subset
Download 40-Class Subset
フルのデータセットが必要な場合は下記のサイトからShuran Songさんへメールで申請するとダウンロードするためのMatlabプログラムが頂けます。
結果
Machineのスペック:
CPU: Intel(R) Core(TM) i7-7700K CPU @ 4.20GHz 8コア
メモリ: 32GB
GPU: GeForce GTX 1080
各結果の精度です。
ModelNetの40クラスのデータを使用しています。
TenosorBoardで確認した学習データとValidationデータの学習曲線です。
TenosrBoardの仕様上(バグ?)、Validationデータの精度が見切れているものがあったので拡大している部分(Validation Accuracy Zoom)も載せています。
画素の問題で数字が見えない点、学習を途中で終了させているため不揃いな点はご了承ください。
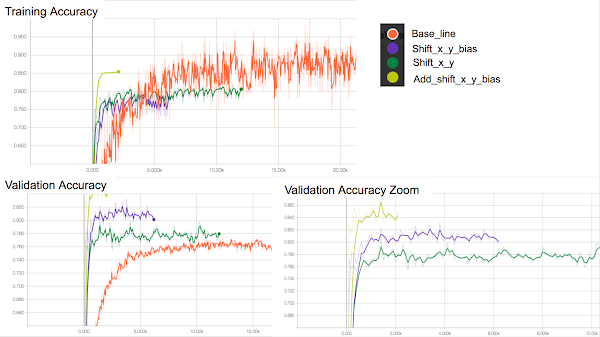
| Method(図上の手法の名前) | 説明 | Training data (accuracy) | Validation data (accuracy) | |
| Base line | 何もなし | 90% | 79% | |
| Shift_x_y | Data augmentation(x-shift, y-shift) | 80% | 80% | |
| Shift_x_y_bias | Data augmentation(x-shift, y-shift) + クラス重み |
80% | 83% | |
| Add_shift_x_y_bias | Data augmentation(x-shift, y-shift) + クラス重み + データ追加(x-shift, y-shift) |
85% | 85% | |
今回のアプローチで特徴的なのはモデルを変えずにデータを加工したり、データの特性を考慮して汎用性を上げている点です。モデルは性能の向上幅が未知数であったり、優秀なモデルでもリソースを大量に消費するため、モデルを改良するというアプローチ行っておりません。
今後
独自の深層学習モデルの検討、図面などの別データへの深層学習の適用、転移学習、Data augmentationを用いて限られた教師データに対して効果的な学習を行う予定です。
最後に
今回、紹介した手法をさらに高度にして世界でも珍しい3次元データの検索エンジンの性能向上したいエンジニアがいらっしゃれば絶賛採用中なので是非、弊社へ応募してください。
参考
Maturana, Daniel, and Sebastian Scherer. "Voxnet: A 3d convolutional neural network for real-time object recognition." Intelligent Robots and Systems (IROS), 2015 IEEE/RSJ International Conference on. IEEE, 2015.
Baydin, Atilim Gunes, et al. "Online Learning Rate Adaptation with Hypergradient Descent." arXiv preprint arXiv:1703.04782 (2017).
Bengio, Yoshua, et al. "Curriculum learning." Proceedings of the 26th annual international conference on machine learning. ACM, 2009.
3D CNN-Action Recognition Part-1
Keras: Deep Learning for Python
3D Object Recognition with Deep Networks
Building powerful image classification models using very little data
Streaming SIMD Extensions
その他の記事
Other Articles

2022/06/03
拡張子に Web アプリを関連付ける File Handling API の使い方

2022/03/22<selectmenu> タグできる子; <select> に代わるカスタマイズ可能なドロップダウンリスト

2022/03/02
Java 15 のテキストブロックを横目に C# 11 の生文字列リテラルを眺めて ECMAScript String dedent プロポーザルを想う

2021/10/13
Angularによる開発をできるだけ型安全にするためのKabukuでの取り組み

2021/09/30
さようなら、Node.js

2021/09/30
Union 型を含むオブジェクト型を代入するときに遭遇しうるTypeScript型チェックの制限について

2021/09/16
[ECMAScript] Pipe operator 論争まとめ – F# か Hack か両方か
2021/07/05
TypeScript v4.3 の機能を使って immutable ライブラリの型付けを頑張る

2021/06/25
Denoでwasmを動かすだけの話

2021/05/18
DOMMatrix: 2D / 3D 変形(アフィン変換)の行列を扱う DOM API

2021/03/29
GoのWASMがライブラリではなくアプリケーションであること

2021/03/26
Pythonプロジェクトの共通のひな形を作る

2021/03/25
インラインスタイルと Tailwind CSS と Tailwind CSS 入力補助ライブラリと Tailwind CSS in JS

2021/03/23
Serverless NEGを使ってApp Engineにカスタムドメインをワイルドカードマッピング

2021/01/07
esbuild の機能が足りないならプラグインを自作すればいいじゃない

2020/08/26
TypeScriptで関数の部分型を理解しよう

2020/06/16
[Web フロントエンド] esbuild が爆速すぎて webpack / Rollup にはもう戻れない

2020/03/19
[Web フロントエンド] Elm に心折れ Mint に癒しを求める
2020/02/28
さようなら、TypeScript enum

2020/02/14
受付のLooking Glassに加えたひと工夫

2020/01/28
カブクエンジニア開発合宿に行ってきました 2020冬

2020/01/30
Renovateで依存ライブラリをリノベーションしよう 〜 Bitbucket編 〜

2019/12/27
Cloud Tasks でも deferred ライブラリが使いたい

2019/12/25
*, ::before, ::after { flex: none; }

2019/12/21
Top-level awaitとDual Package Hazard

2019/12/20
Three.jsからWebGLまで行きて帰りし物語

2019/12/18
Three.jsに入門+手を検出してAR.jsと組み合わせてみた

2019/12/04
WebXR AR Paint その2

2019/11/06
GraphQLの入門書を翻訳しました

2019/09/20
Kabuku Connect 即時見積機能のバックエンド開発

2019/08/14
Maker Faire Tokyo 2019でARゲームを出展しました

2019/07/25
夏休みだョ!WebAssembly Proposal全員集合!!

2019/07/08
鵜呑みにしないで! —— 書籍『クリーンアーキテクチャ』所感 ≪null 篇≫

2019/07/03
W3C Workshop on Web Games参加レポート

2019/06/28
TypeScriptでObject.assign()に正しい型をつける

2019/06/25
カブクエンジニア開発合宿に行ってきました 2019夏

2019/06/21
Hola! KubeCon Europe 2019の参加レポート

2019/06/19
Clean Resume きれいな環境できれいな履歴書を作成する

2019/05/20
[Web フロントエンド] 状態更新ロジックをフレームワークから独立させる

2019/04/16
C++のenable_shared_from_thisを使う

2019/04/12
OpenAPI 3 ファーストな Web アプリケーション開発(Python で API 編)

2019/04/08
WebGLでレイマーチングを使ったCSGを実現する

2019/03/29
その1 Jetson TX2でk3s(枯山水)を動かしてみた

2019/04/02
『エンジニア採用最前線』に感化されて2週間でエンジニア主導の求人票更新フローを構築した話

2019/03/27
任意のブラウザ上でJestで書いたテストを実行する

2019/02/08
TypeScript で “radian” と “degree” を間違えないようにする

2019/02/05
Python3でGoogle Cloud ML Engineをローカルで動作する方法

2019/01/18
SIGGRAPH Asia 2018 参加レポート
2019/01/08
お正月だョ!ECMAScript Proposal全員集合!!

2019/01/08
カブクエンジニア開発合宿に行ってきました 2018秋

2018/12/25
OpenAPI 3 ファーストな Web アプリケーション開発(環境編)

2018/12/23
いまMLKitカスタムモデル(TF Lite)は使えるのか

2018/12/21
[IoT] Docker on JetsonでMQTTを使ってCloud IoT Coreと通信する

2018/12/11
TypeScriptで実現する型安全な多言語対応(Angularを例に)

2018/12/05
GASでCompute Engineの時間に応じた自動停止/起動ツールを作成する 〜GASで簡単に好きなGoogle APIを叩く方法〜

2018/12/02
single quotes な Black を vendoring して packaging

2018/11/14
3次元データに2次元データの深層学習の技術(Inception V3, ResNet)を適用

2018/11/04
Node Knockout 2018 に参戦しました

2018/10/24
SIGGRAPH 2018参加レポート-後編(VR/AR)

2018/10/11
Angular 4アプリケーションをAngular 6に移行する

2018/10/05
SIGGRAPH 2018参加レポート-特別編(VR@50)

2018/10/03
Three.jsでVRしたい

2018/10/02
SIGGRAPH 2018参加レポート-前編

2018/09/27
ズーム可能なSVGを実装する方法の解説

2018/09/25
Kerasを用いた複数入力モデル精度向上のためのTips

2018/09/21
競技プログラミングの勉強会を開催している話

2018/09/19
Ladder Netwoksによる半教師あり学習

2018/08/10
「Maker Faire Tokyo 2018」に出展しました

2018/08/02
Kerasを用いた複数時系列データを1つの深層学習モデルで学習させる方法

2018/07/26
Apollo GraphQLでWebサービスを開発してわかったこと

2018/07/19
【深層学習】時系列データに対する1次元畳み込み層の出力を可視化

2018/07/11
きたない requirements.txt から Pipenv への移行

2018/06/26
CSS Houdiniを味見する

2018/06/25
不確実性を考慮した時系列データ予測

2018/06/20
Google Colaboratory を自分のマシンで走らせる

2018/06/18
Go言語でWebAssembly

2018/06/15
カブクエンジニア開発合宿に行ってきました 2018春

2018/06/08
2018 年の tree shaking

2018/06/07
隠れマルコフモデル 入門

2018/05/30
DASKによる探索的データ分析(EDA)

2018/05/10
TensorFlowをソースからビルドする方法とその効果

2018/04/23
EGLとOpenGLを使用するコードのビルド方法〜libGLからlibOpenGLへ

2018/04/23
技術書典4にサークル参加してきました

2018/04/13
Python で Cura をバッチ実行するためには

2018/04/04
ARCoreで3Dプリント風エフェクトを実現する〜呪文による積層造形映像制作の舞台裏〜

2018/04/02
深層学習を用いた時系列データにおける異常検知

2018/04/01
音声ユーザーインターフェースを用いた新方式積層造形装置の提案

2018/03/31
Container builderでコンテナイメージをBuildしてSlackで結果を受け取る開発スタイルが捗る
2018/03/23
ngUpgrade を使って AngularJS から Angular に移行

2018/03/14
Three.jsのパフォーマンスTips

2018/02/14
C++17の新機能を試す〜その1「3次元版hypot」

2018/01/17
時系列データにおける異常検知

2018/01/11
異常検知の基礎

2018/01/09
three.ar.jsを使ったスマホAR入門

2017/12/17
Python OpenAPIライブラリ bravado-core の発展的な使い方

2017/12/15
WebAssembly(wat)を手書きする
2017/12/14
AngularJS を Angular に移行: ng-annotate 相当の機能を TypeScrpt ファイルに適用

2017/12/08
Android Thingsで4足ロボットを作る ~ Android ThingsとPCA9685でサーボ制御)

2017/12/06
Raspberry PIとDialogflow & Google Cloud Platformを利用した、3Dプリンターボット(仮)の開発 (概要編)

2017/11/20
カブクエンジニア開発合宿に行ってきました 2017秋

2017/10/19
Android Thingsを使って3Dプリント戦車を作ろう ① ハードウェア準備編

2017/10/13
第2回 魁!! GPUクラスタ on GKE ~PodからGPUを使う編~

2017/10/05
第1回 魁!! GPUクラスタ on GKE ~GPUクラスタ構築編~

2017/09/13
「Maker Faire Tokyo 2017」に出展しました。

2017/09/11
PyConJP2017に参加しました

2017/09/08
bravado-coreによるOpenAPIを利用したPythonアプリケーション開発

2017/08/23
OpenAPIのご紹介

2017/08/18
EuroPython2017で2名登壇しました。

2017/07/26
3DプリンターでLチカ

2017/07/03
Three.js r86で何が変わったのか

2017/06/01
カブクエンジニア開発合宿に行ってきました 2017春

2017/05/08
Three.js r85で何が変わったのか

2017/04/10
GCPのGPUインスタンスでレンダリングを高速化

2017/02/07
Three.js r84で何が変わったのか

2017/01/27
Google App EngineのFlexible EnvironmentにTmpfsを導入する
2016/12/21
Three.js r83で何が変わったのか

2016/12/02
Three.jsでのクリッピング平面の利用
2016/11/08
Three.js r82で何が変わったのか

2016/12/17
SIGGRAPH 2016 レポート

2016/11/02
カブクエンジニア開発合宿に行ってきました 2016秋

2016/10/28
PyConJP2016 行きました

2016/10/17
EuroPython2016で登壇しました
2016/10/13
Angular 2.0.0ファイナルへのアップグレード
2016/10/04
Three.js r81で何が変わったのか

2016/09/14
カブクのエンジニアインターンシッププログラムについての詩

2016/09/05
カブクのエンジニアインターンとして3ヶ月でやった事 〜高橋知成の場合〜
2016/08/30
Three.js r80で何が変わったのか
2016/07/15
Three.js r79で何が変わったのか

2016/06/02
Vulkanを試してみた

2016/05/20
MakerGoの作り方

2016/05/08
TensorFlow on DockerでGPUを使えるようにする方法

2016/04/27
Blenderの3DデータをMinecraftに送りこむ

2016/04/20
Tensorflowを使ったDeep LearningにおけるGPU性能調査
関連職種
Recruit